======= ======================================
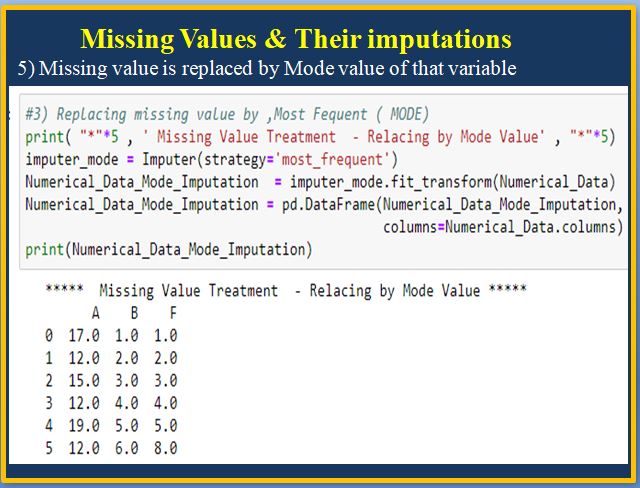
2) Missing Values
=================== ===========================
Scaling
Some Additional things in Jupyter Note Book
Pandas Very useful methods for data analysis
1) Importing Pandas library & looking at versions.

-------
2) Reading the data which resides in Excel file.

-------
3) DF.[Column].unique(), get unique records in the column
# the following code gets unique records of column, 'Region' , values are :['Central', 'East', 'West', 'South'],
type: Numpy array
code: type(Sample_Superstore_Updated['Region'].unique())
 -------
-------
3)
4) DF.info() function gets the information about the DataFrame, it includes number of records, Index, Data type of the input(DataFrame), number of not null records in each column, data type
Columns for each different kind of data type.












# removing stop words
# import nltk
# from nltk.corpus import stopwords
# stop_words_1 = list(set(stopwords.words('english')))
# import spacy
# en = spacy.load('en_core_web_sm')
# stop_words_2 = list(set(en.Defaults.stop_words))
# stop_words_total = list(set(stop_words_2 + stop_words_1))
# # print( "len(stop_words):" , len(stop_words_total),
# # "\nlen(stop_words_2)-SPACY:" , len(stop_words_2),
# # "\nlen(stop_words_1)-NLTK:" , len(stop_words_1)
# # )
# removing stop words
#https://gist.github.com/sebleier/554280
# import nltk
# from nltk.corpus import stopwords
# stop_words_1 = list(set(stopwords.words('english')))
# import spacy
# en = spacy.load('en_core_web_sm')
# stop_words_2 = list(set(en.Defaults.stop_words))
# stop_words_total = list(set(stop_words_2 + stop_words_1))
# print( "len(stop_words):" , len(stop_words_total),
# "\nlen(stop_words_2)-SPACY:" , len(stop_words_2),
# "\nlen(stop_words_1)-NLTK:" , len(stop_words_1)
# )
# import requests
# stopwords_list = requests.get("https://gist.githubusercontent.com/rg089/35e00abf8941d72d419224cfd5b5925d/raw/12d899b70156fd0041fa9778d657330b024b959c/stopwords.txt").content
# stopwords = set(stopwords_list.decode().splitlines())
# stopwords





















{kind=link}